In high load teams, there is this common thread that appears again and again: "we don't have time to fully automate this SOP". This happens for problems that are rare (a few time a year), are low impact (only 0.0x% of clients/requests/$ impacted) or high engineering cost to fix. Usually, if your organization is effective, you'll take note of the recurring problem, add it to a backlog and maybe provide a proper "long term fix" for the next sprint. Oftentimes this problem stays in the backlog forever.
In very productive teams, senior engineers and management fosters a culture empowering the engineers to semi-automate the mitigation for this type of recurring problems, it could be a quick python script in a shared folder, a well written SOP for newcomers, or simply tune the alert level if there is no action item.
This is beautifully summarized in the now famous XKCD:
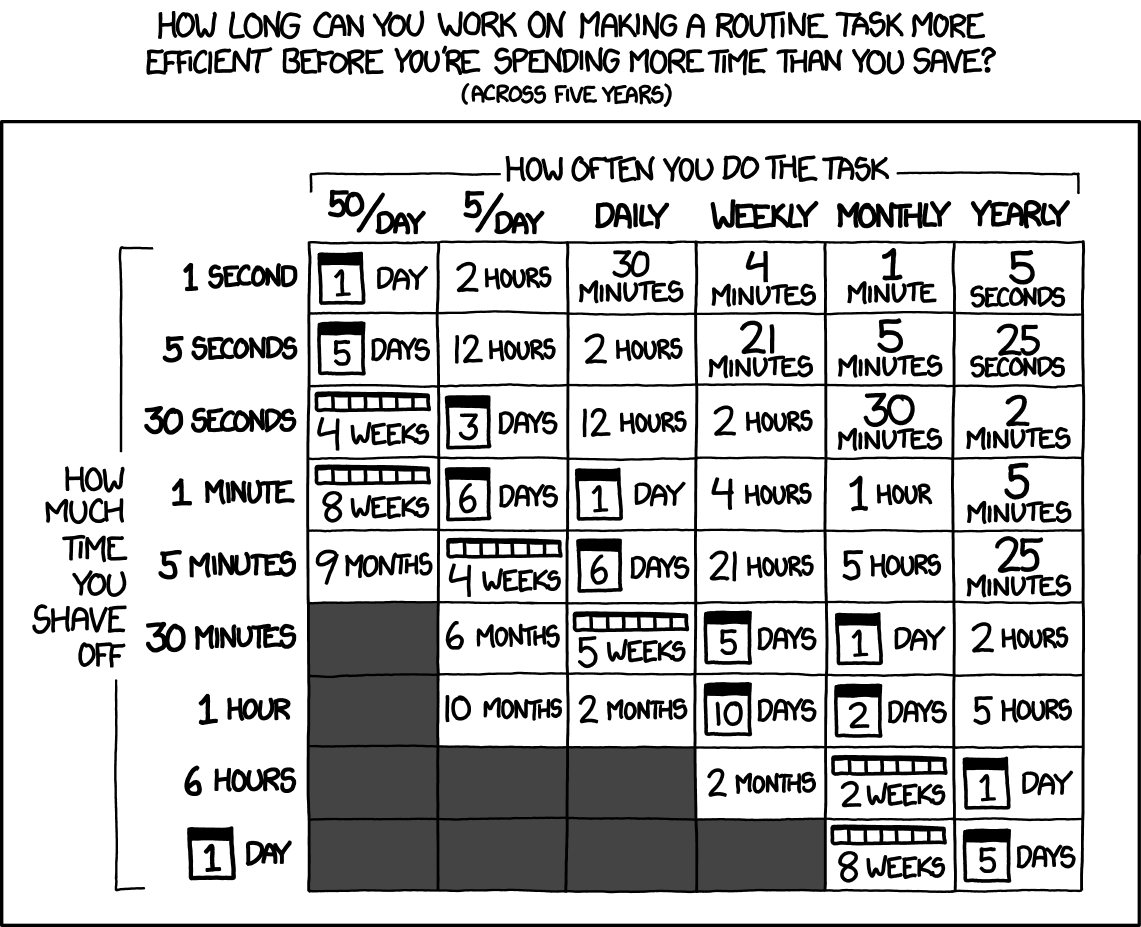
I'd like to make the case with LLM-agent tools coming into the engineering toolkit, effective teams could leverage, them to tackle issues that were too expensive to tackle today, which could effectively improve the quality of tech products for the users.
Applying the XKCD table to engineering oncall issue mitigation, we can rank the ways of solving a recurring issue in the following order:

On the left, manual mitigations are cheap do to once, this is when the oncall will bounce the fleet, or manually update a configuration to partially mitigate the issue, this can be done in a short amount of time (~15 minutes). Sometimes, this action is also a loosely defined set of investigation steps, that require fetching, combining data from multiple source before taking a decision. It generally only fixes the issue once, and the same action might be needed again if the issue happens again.
In between, there are semi-automated, or "scripted mitigation". Scripted mitigations usually are created by team when a recurring issue pass a certain threshold of either complexity (too many items to fix) or a threshold of frequency. Scripts take more time to write the first time, from a few minutes to a few hours, but once created, they can save substantial time on subsequent occurrences. As examples: scripts to re-drive a few asynchronous events, scripts to update multiple objects in a database in an invalid state.
Finally, generally, the preferred approach is a systematic bug fix or system redesign to make the error case fully disappear. Such solution range take from hours, days, or weeks of work to be implemented, depending on the complexity. For rare, low-impact issues (that still impact a few unhappy users), this type of fix is rare prioritized, unless another higher impact issue allow the team to bundle the bug fix with the other issue.
In a perfect world, teams would reach for this last solution as much as possible, but time-constrains and other priorities often time only allow to reach for a proper resolution only if the impact pass a certain threshold of impact.
The thesis I'm bringing is that LLM based tools which are getting better and better at writing code snippets, reading and compiling from unstructured data source can be (and should be) used as a new automation level in operational excellence. On the OPEX/CAPEX spectrum, such tools allow us to close the gap between manual incident mitigation and automated mitigation:

LLM agents can be seen as a new tool for operational teams, serving as helpers for mitigating low-impact issues while software engineers focus most of their attention on higher-impact work during busy on-call rotations.
When writing a mitigation script would have taken a couple of hours in the past (with proper testing, edge case handling, etc.), LLM agents can give engineers a head start. They write the boilerplate, handle the core business logic of the script, and generate data for script testing before oncall can validate and execute it in a production environment. For an issue that impacts only a few user a month, the oncall Engineer may never had the time to investigate the issue. Or if they could investigate the issue, they may have judged that performing a mitigation or fix would be too much effort compared to the impact, thus leaving the issue unmitigated or partially mitigated.
Another task that takes time for software engineers is the process of following loosely defined SOPs. These SOPs are can sometime be vague, and require investigation work (otherwise they would have been automated sic). With proper guardrails, some investigation SOPs (checking multiple log streams, databases, API endpoints…) can now be half-automated. The LLM agent to do most of the legwork of combining unstructured data sources, summarizing issues, bucketizing problems, and report the findings to the oncall. In this case, the LLM serves as an approximate interpreter of the SOP, something that was qualitatively impossible in the past.
Note that high-impact operational work still benefit from GenAI tools (and for similar reasons). The point I'm making here is, by reducing the cost of investigating, analyzing and mitigating low-impact issues, LLM may be a tool that ultimately improve the overall software operational quality for high TPS systems. Such systems, often accumulate over time a big backlog of detected, but unmitigated bugs, which if were fully tackled would generally improve the service quality in a measurable way.
Finally, please consider that I'm not advocating in leaving LLM agents loose access to production environment. Before adding any agent to their workflow, teams should assess their security posture, especially in the new class of security issues that LLM agents bring security engineering. Further, as an industry, we should recognize that LLM tools are not always a net productivity gain, and the same should apply when designing an agent optimized for on-call. Hopefully good engineering practices will emerge with time.